
I met Daniel Labelle through his video “If people sprinted instead of walked“. Suddenly I shared with my running mates and started to follow Daniel’s Youtube channel. The explanation of the situation was extraordinary which was called “physical comedy” I learned later. The channel is one of the fastest-growing Youtube channels. Once videos were released, they got millions of views quickly. Although he has Tiktok (27.6M followers), Youtube (16.1M), and Instagram (2.8M) accounts, he did not create any personal Twitter page. Since I spent most of my social media time on Twitter, it would be great if I can watch the videos on the Twitter feed whenever he published them.
After a quick google search, I also realized nobody had created an account for this (maybe nobody has this much spare time :p). Anyways, this content really deserves to be on Twitter. I have created a fan page and started to copy videos to the Twitter account. But manually downloading/uploading the videos and continuously checking new videos’ releases were really time-consuming. I thought, why should a bot not do it instead of me?
The idea of creating a bot as simple as this,
- Check continuously is there a new video?
- if yes: download it from youtube and upload it to Twitter
- if no: do nothing
Selecting Libraries
Rather than using the Twitter and Youtube APIs directly, I preferred to use a wrapper library to make it simple. Because my plan was to complete such work in almost one hour. I preferred to use Tweepy, Scrapetube, and Pytube (all of them are in Python programming language that’s why I have implemented the bot in Python)
Getting an Access Key
The most difficult part was getting access keys from Twitter. Twitter requires explanations of your purpose for asking API keys. At first, I did not tell them in detail, and it was refused. Then I gave more information about the data collection and processing steps. Then, the request was accepted. To pass this step once, you must be explanatory.
The Code
The implemented algorithm has a few rows. Most of the low-level processes dealt with the APIs. Comments on the code explain what it does.
import tweepy
import scrapetube
from pytube import YouTube
import json
import os
# read credentials
f = open(os.getcwd() + '/credentials.json')
creds = json.load(f)
# connect to twitter api
auth = tweepy.OAuthHandler(creds['twitter']['consumer_key'], creds['twitter']['consumer_secret'])
auth.set_access_token(creds['twitter']['access_token'], creds['twitter']['access_secret'])
api = tweepy.API(auth)
# get last video tweet
latest_tweet = api.user_timeline(count=1)[0].text
# get rid of the 'https://t.co/'
latest_twitter_video_title = latest_tweet.split(' https://t.co/')[0]
# get latest channel video information
youtube_videos = scrapetube.get_channel(channel_url=creds['youtube']['channel_url'], limit=1)
latest_youtube_video_title = ''
latest_youtube_video_id = ''
for video in youtube_videos:
latest_youtube_video_title = video['title']['runs'][0]['text']
latest_youtube_video_id = video['videoId']
# detect is there a new video
if (latest_twitter_video_title != latest_youtube_video_title):
youtube_link = "https://www.youtube.com/watch?v=" + latest_youtube_video_id
video_filename = latest_youtube_video_id + '.mp4'
video_path = os.getcwd() + '/' + video_filename
output_path = os.getcwd()
try:
# download te video
yt = YouTube(youtube_link).streams.filter(progressive=True, file_extension='mp4').order_by('resolution').desc().first().download(output_path=output_path, filename=video_filename)
# upload the video to twitter
media = api.media_upload(video_path, media_category='tweet_video')
# send tweet
api.update_status(status=latest_youtube_video_title, media_ids=[media.media_id])
# delete the video
os.remove(video_path)
print('New video uploaded')
except:
# delete the video
os.remove(video_path)
print("Error occured")
else:
print('No new video')
Deployment
After testing the code locally, I pulled my repo to the AWS machine and created a cronjob that runs the script every hour.
0 * * * * /usr/bin/python3 /home/ubuntu/scripts/daniellabelle-bot/bot.py
Final Comments
Actually, scrapping the data from YouTube to Twitter is not a challenging task. But it is exciting to make manual operations automated. Now Daniel’s fan page is running itself. It has almost 1,000 followers. And now I can watch videos on Twitter shared by a bot that is created by me 🙂
Recently, Daniel sent me a Direct Message in which he asked to remove one of his videos. Because -most probably-, he changed his mind and removed his last video from social media accounts. But the bot copied the data to Twitter faster than Danielle’s removal operation 🙂
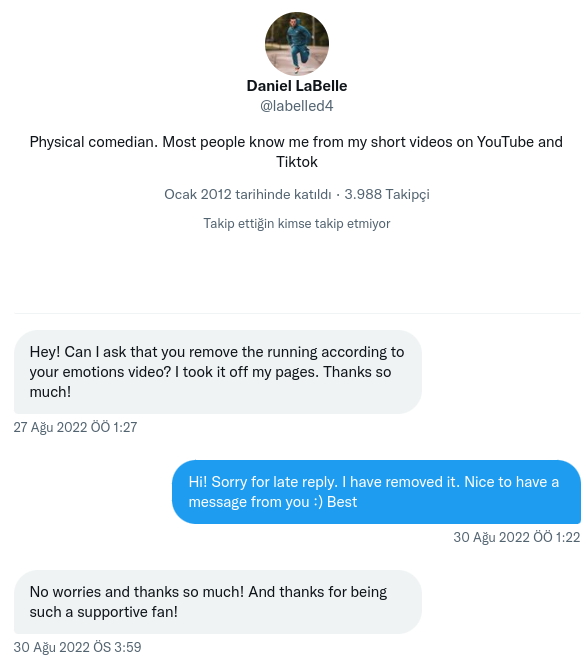
The implementation procedure was fun for me. I have abstracted the code that can be used for any Youtube & Twitter channels. You can find the links below.
Repo: https://github.com/ahmetbersoz/twitter-youtube-sync-bot
Twitter page: https://twitter.com/DanielLabelleFP
Best.